Which is the best Speech-to-text AI in 2022?
A comparison of some of the best speech-to-text AI models in 2022 - Assembly AI, Amazon Transcribe, Google Speech To Text, Vosk, OpenAI’s Whisper

Table of Contents
As Artificial Intelligence (AI) continues to evolve and become increasingly integrated into our everyday lives, speech to text is becoming more and more prevalent. In 2022, there will be a wide array of speech to text AI’s that are available for developers to use.
In this article I’ll share my findings on choosing the most suitable AI Speech-to-text engine.
In order to do that, let me first define a couple of criteria that I find most valuable. Those of course might be different for your needs, for example you may value ease of use more than cost, which will skew the decision in favor of cloud-based solutions.
Here are my main decision drivers, ordered by importance:
- Result accuracy -
Very important - Cost -
Very important - Ease of use -
Somewhat important - Performance -
Somewhat important - Extra features - speaker recognition, punctuation, profanity masking, automatic chaptering -
Nice to have
And here are the contenders:
- Assembly AI
- Amazon Transcribe
- Google Speech To Text
- Vosk
- OpenAI’s Whisper
Note that I’m not affiliated in any way with any of these and the information bellow is the result of my personal findings when deciding which technology to use for a project. And I’m not even close to being a machine learning expert, so this is the point of view of an web developer that wants to simply use those technologies.
I used this YouTube video, which is around 10 minutes long and contains generic dialog as well as a lot of technical terms or names.
Best Python IDE: Vim, Emacs, PyCharm, or Visual Studio Code? | Guido van Rossum and Lex Fridman
Findings
-
Assembly AI
AssemblyAI | #1 API Platform for AI Models
Assembly AI is a cloud-based solution that provides not only text-to-speech but also a variety of other NLP services.
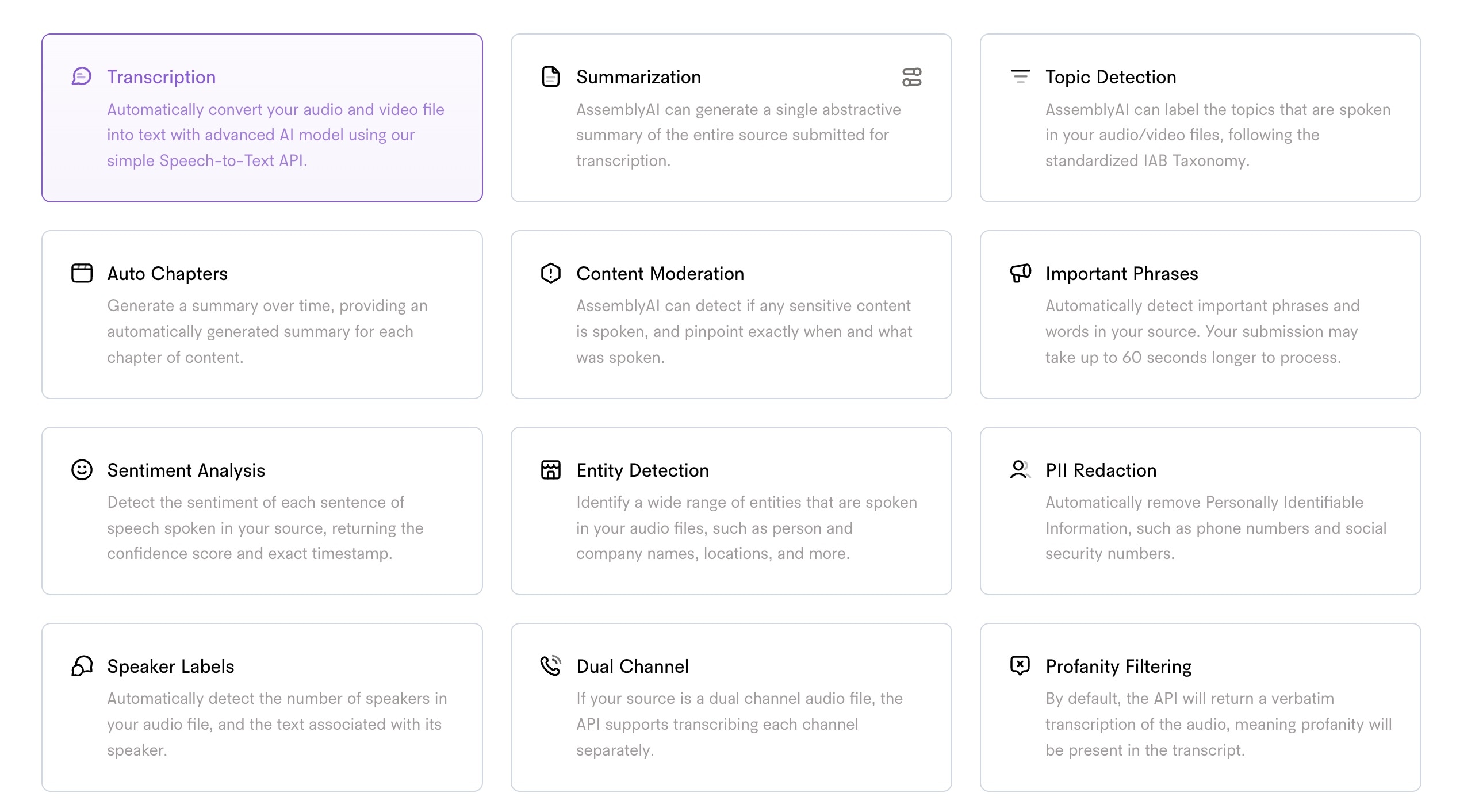
Here’s a link to their playground that I used for testing it https://www.assemblyai.com/playground
- Result accuracy - Amazing, almost no issues, even when dealing with technical terms or names. It capitalizes accurately and has proper punctuation.

- Cost - it’s a cloud-based service, so it’s natural to be quite expensive. It’s comparable to other cloud based solutions at $0.015/minute, but that’s only for the core transcription service. If you need the extra Audio Intelligence features you need quite a bit more budget with the cost of $0.035/minute. But of course this could be worth it for the result accuracy and the peace of mind that comes with using a managed service
- Ease of use - the plus side of cloud-based solutions is that it’s very easy to use them - you just call an API and you’re done - no infrastructure to manage.
- Performance - they advertise it as around 20% of the running time, which sounds very good
- Extra features - it has the fullest audio intelligence feature set of all options, if you have the budget for the more expensive plan
Verdict: Assembly AI’s quality and large feature set would be my choice if I needed a top-notch cloud-based solution and budget wasn’t a problem.
-
Amazon Transcribe
Amazon Transcribe – Speech to Text - AWS
This is AWS’s speech to text solution, which might be the obvious choice for many solutions that are already in the AWS ecosystem in one way or another.
- Result accuracy - it’s a decent, way worse than Assembly AI, but workable enough for simple use cases. It has proper punctuation and mostly good capitalization. It doesn’t handle technical terms or names well
- Cost - it is also a cloud-based solution, so it’s quite costly at $0.024/minute. But the cost goes down the more minutes you use per month, down to $0,0077/minute if you use more than 10 million minutes per month. Which is a good deal if you have a lot of audio to transcribe
- Performance - very good - the 10-minute test video was processed for 2 minutes and 20 seconds, which is around 20% of the running time.
- Extra features - you have profanity masking, speaker recognition out of the box
Verdict: I would pick Amazon Transcribe if there’s a large volume of audio to transcribe each month and it doesn’t matter that the quality is not as good as it can be.
-
Google Speech-to-Text
Speech-to-Text: Automatic Speech Recognition | Google Cloud
Google’s solution is widely known and, in general, Google has a reputation of delivering top-notch AI solutions. There’s a free demo on the page where I uploaded my video and saw the results right away.
- Result accuracy - Good, not as good as AssemblyAI, but definitely better than Amazon. Handles technical terms good most of the time, but misses them here and there.
- Cost - it is also a cloud-based solution, so it’s quite costly at $0.016/minute, and that is the cheaper option, which allows Google to record your sent audio and use it to “help improve the machine learning models”. It has as more expensive option at $0.024/minute, which is more private.
- Ease of use - again, as a cloud-based solutions it’s very easy to use
- Performance - the test I did had decent performance, considering it’s a free demo page - a 1 minute audio (that was the max demo length) was done in around 30s, with speaker recognition and punctuation turned on
- Extra features - you get speaker recognition and punctuation readily available
- Other pros - it’s Google, so there’s a higher chance that it will be more available and reliable as a service than other providers given their massive infrastructure and talent
- Other cons - it’s Google, and a lot of people have privacy concerns with that.
Verdict: Google’s solution is a pretty stable choice if you want a cloud based solution, but you’d have to really consider if going with Assembly AI isn’t worth it, since it has better quality.
-
Vosk
VOSK Offline Speech Recognition API
This is the first open source option on the list. As such, it’s completely free to use, but you have to manage your own infrastructure to do that. This might be considered a pro to some people, because of the control and privacy, and a con to other, because of the effort needed to set it up and manage it. But it has a pretty active community, so I’m sure if you encounter any problems you will not find it hard to find solutions.
Another big plus to Vosk is that there’s a Web Assembly version, which means you can run it in the browser if you need. It’s not as fast and it required the user to download a pretty large model file, but it can be a great way to save costs, be private, and have a performant solution, by offloading the work to the user’s machine. You can test the web demo here https://ccoreilly.github.io/vosk-browser/
- Result accuracy - decent, similar to Amazon Transcribe. Note that I tested larger models, the smaller 40mb models is not that good and is worse than Amazon Transcribe. There is no capitalization or punctuation, but if you want to tinker with it you can use other wasm solutions to handle that
- Cost - it’s a self-hosted solution, so in general it’s less expensive than cloud-based counterparts. But of course you have to factor in the cost of managing it. You’re not really paying for a service or an application, you’d be paying for the servers than run it. Or you can run it client-side in the browser completely free
- Ease of use - as self-hosted solution it’s harder to set it up and you have to manage the servers that run it. You don’t have to be a machine learning expert to use it, any mid backend engineer should be able to set it up, but you can’t compare it to just calling an external API.
- Performance - I tested the WASM version, so the actual one might be a bit faster. In the browser I got a speed of around 20% of the running time on my Macbook M1 Pro, which is very good and comparable to the cloud vendors.
Verdict: it’s a decent open source solution and a great one if you need to run it in the browser. But I’d look more at the next option otherwise
-
Whisper by OpenAI
GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
Whisper is a relatively new entry, made by the OpenAI team, which are behind one of the most cutting edge technologies in the AI space right now
It’s also open source so, you can read the introduction to Vosk if you skipped it.
There’s a C++ port of Whisper, that is compilable to Web Assembly, but it’s not official and is just a hobby project for now https://github.com/ggerganov/whisper.cpp . So you can technically run it in the browser as well, but it’s questionable if that’s the right choice if you’re looking for a long-term maintainable and stable solution. Of course if needed you can also take the initiative to help the project if you have enough ML, C++ and WASM knowledge. There’s one big benefit of using that instead of the Vosk’s wasm version - that the Whisper’s models are a lot smaller, which is a very good thing, because you have to download them on every browser that uses it.
- Result accuracy - amazing, comparable to Assembly AI, even with the smaller models. And you can increase the timing precision, so that, for example you get the timestamps of each word.

- Cost - again, as a self-hosted solution, it’s less expensive than cloud-based counterparts. But of course you have to factor in the cost of managing it. You’re not really paying for a service or an application, you’d be paying for the servers than run it. Or you can run it client-side in the browser completely free
- Ease of use - again, as self-hosted solution it’s harder to set it up and you have to manage the servers that run it
- Performance - around 20% of the running time on my Macbook M1 Pro, which is very good and comparable to the cloud vendors.
- Extra features - no speaker recognition, but you can use other tools to do that https://github.com/openai/whisper/discussions/264 .
Verdict: it’s an amazing open source project and that would be my go-to option if you’re looking for a self-hosted or browser-based solution.
Conclusion
In conclusion, when it comes to finding the best Speech-to-Text AI for 2022, there are a variety of options to choose from, each with it’s own use cases. Deciding which to use depends on your requirements, budget and use case.
Assembly AI is a top-notch cloud-based solution that provides an excellent result accuracy and comes with a wide range of audio intelligence features.
Amazon Transcribe is a good choice for those who need to transcribe large volumes of audio, but have a lower requirement for accuracy.
Google Speech-to-Text offers good result accuracy, as well as speaker recognition and punctuation out of the box.
Vosk is a self-hosted open-source solution that’s comparable to Amazon Transcribe in quality.
Finally, Whisper by OpenAI is another open-source solution that offers amazing accuracy and is a great choice for those looking for a self-hosted or browser-based solution. This will be my choice for the project.

Anton Mihaylov